When to use it
- The user request is ambiguous or multi-step and you want the system to decide what to do before executing.
- Different parts of the task require different agents or MCP servers (retrieve context, analyse, write, verify).
- You need visibility into the plan, intermediate results, and token spend for each subtask.
- You want to switch between full upfront planning and iterative planning based on feedback.
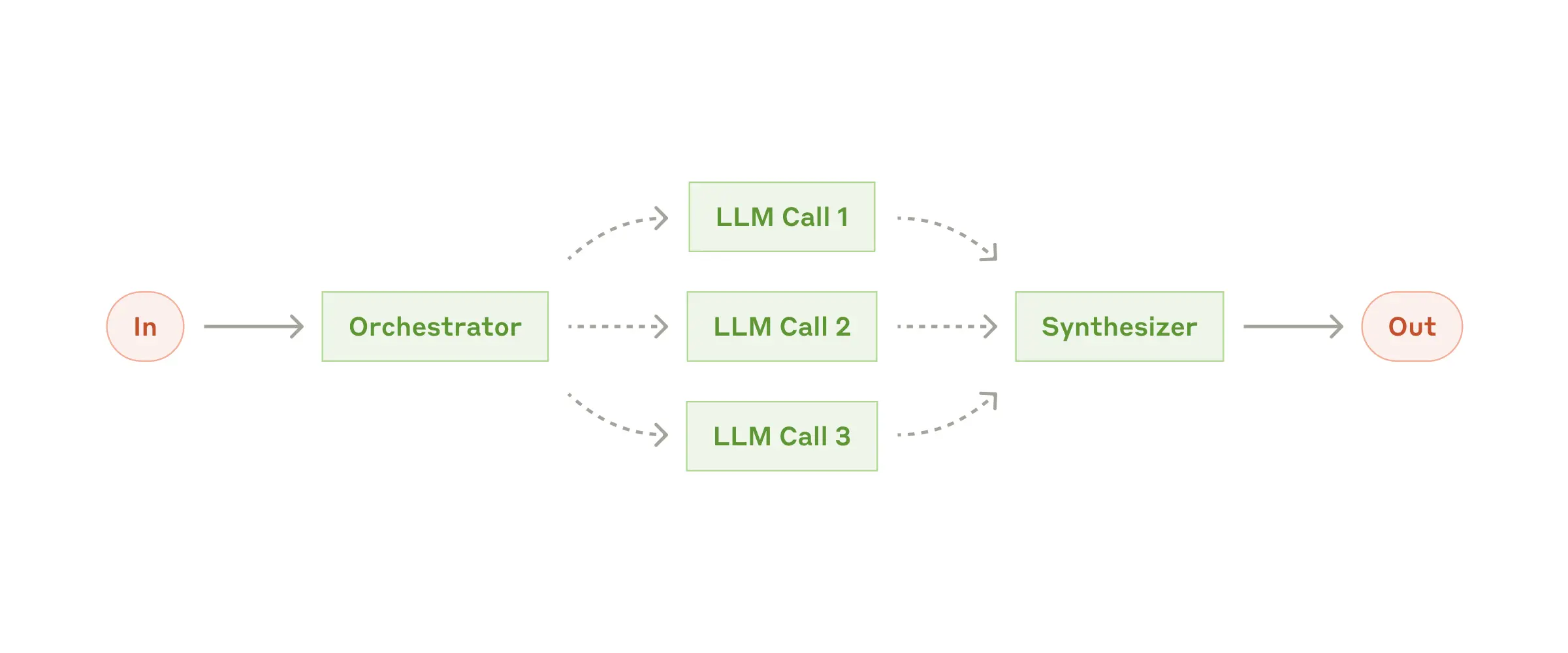
Core roles
create_orchestrator returns an Orchestrator AugmentedLLM composed of:
- Planner – an LLM that produces a
Planwith sequentialSteps and parallelTasks. You can provide your own planner agent or use the default prompt. - Workers – the
available_agentsyou pass in. Each step selects whichever agent (or MCP server) best fits the subtask. - Synthesizer – combines the outputs of each step into the final result. Provide your own synthesizer agent to bias tone or format.
Quick start
await orchestrator.execute(objective) when you want full access to the PlanResult: each step, the tasks that ran, agent selections, and intermediate outputs.
Execution modes
plan_type="full"builds the entire plan upfront, then executes it step by step. Use this when the task is well understood and you want deterministic execution.plan_type="iterative"plans one step at a time, feeding the latest results back into the planner. Ideal for exploratory work or when new context appears during execution.- Guardrails:
request_params.max_iterationscaps the number of planner loops.request_params.maxTokensdefaults to 16K to accommodate plans and long syntheses.request_params.use_historyis disabled—context is managed manually between steps.
Customising prompts and roles
- Pass
plannerorsynthesizerarguments to supply pre-built agents (with their own tools or model preferences). - Use
OrchestratorOverridesto replace any prompt template:get_full_plan_prompt/get_iterative_plan_prompt: plug in your own prompt builders if you want richer task schemas or intermediate metadata.get_task_prompt: control the system prompt given to each worker before it runs.get_synthesize_plan_prompt: change the final aggregation format (JSON, Markdown, HTML).
- The orchestrator automatically loads tool availability from the context; include
server_nameson yourAgentSpecs so planner prompts explain what each worker can do.
Observability and debugging
- Enable tracing (
otel.enabled: true) to capture spans for planning, each step’s parallel execution, and synthesis. Each task records which agent ran, token usage, and outputs. - Call
await orchestrator.get_token_node()to inspect the token/cost tree—each planner iteration and worker invocation is a child node. - The
PlanResultreturned byexecutecontainsstep_resultswith every intermediate output. Persist it for audit trails or UX side panels.
Integration tips
- Wrap the orchestrator with
@app.async_toolto expose it as an MCP tool that other agents (or Anthropic Claude) can call. - Combine with the Parallel pattern by using a
ParallelLLMas a worker inside a step. - For durable execution, point
execution_enginetotemporaland follow the Temporal examples. - Need policy, budgeting, or knowledge extraction? Reach for the Deep Research pattern, which builds on this orchestrator.
Example projects
- workflow_orchestrator_worker – student essay grader that plans retrieval, analysis, and report writing.
- Temporal orchestrator – durable planner with pause/resume.
- workflow_deep_orchestrator – extended planner with dashboards, budgets, and policy enforcement.