When to use it
- Quality matters and you need an automated reviewer to approve or demand revisions.
- You have an explicit rubric (score threshold, policy checklist, guardrail) that can be evaluated programmatically.
- You want traceability: each attempt, its score, and the feedback that drove the next revision.
- You need to wrap another workflow (router, orchestrator, parallel, even a deterministic function) with an evaluation loop.
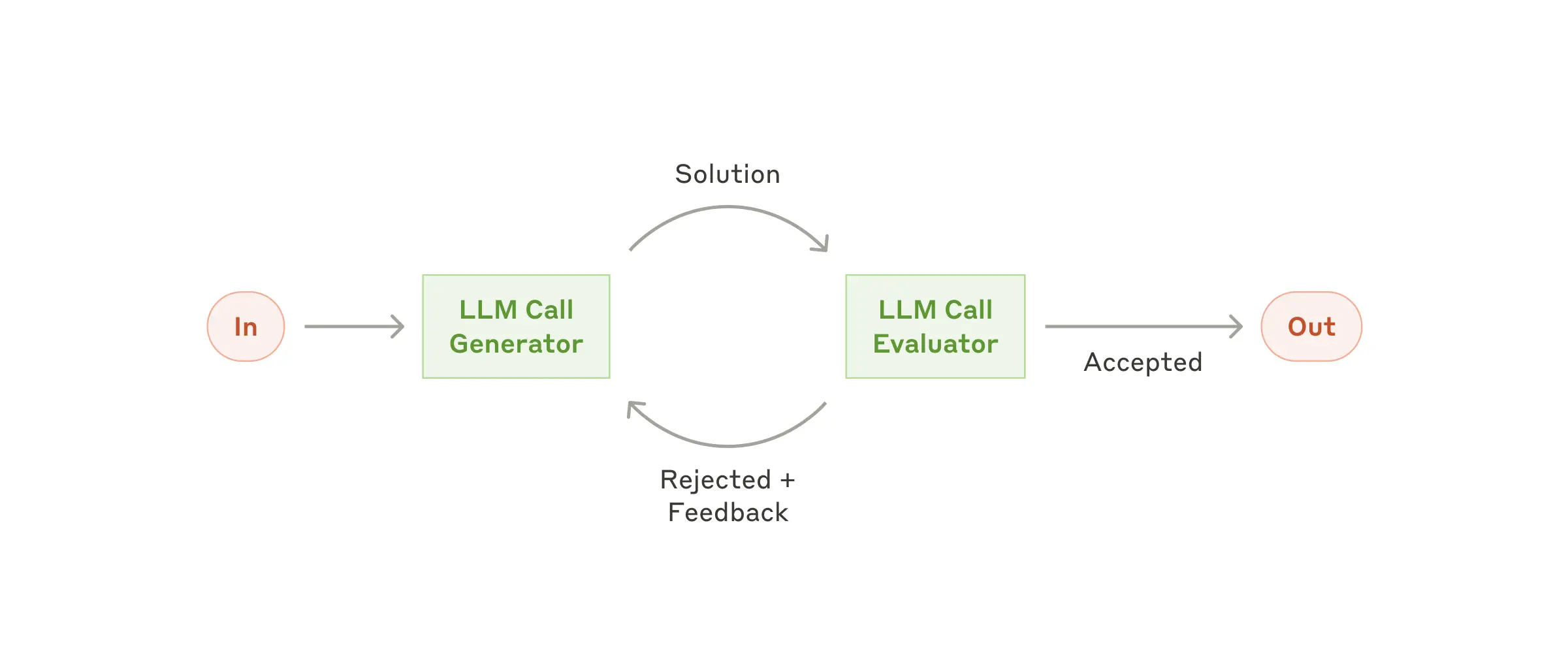
How the loop works
create_evaluator_optimizer_llm returns an EvaluatorOptimizerLLM that:
- Calls the
optimizerto generate an initial response. - Sends the response to the
evaluator, which returns anEvaluationResultwith:rating: aQualityRating(POOR,FAIR,GOOD,EXCELLENTmapped to 0–3).feedback: free-form comments.needs_improvement: boolean.focus_areas: list of bullet points for the next iteration.
- If the rating meets
min_rating, the loop stops. Otherwise it regenerates with the optimizer, incorporating the evaluator’s feedback, untilmax_refinementsis reached. - Every attempt is recorded in
refinement_historyfor audit or UI display.
Quick start
AgentSpec. For evaluators, strings are allowed: if you pass a literal string, the factory spins up an evaluator agent using that instruction.
Configuration knobs
min_rating: numeric threshold (0–3). Set toNoneto keep all iterations and let a human pick the best attempt.max_refinements: hard cap on iteration count; default is 3.evaluator: acceptAgentSpec,Agent,AugmentedLLM, or string instruction. Use this to plug in policy engines or MCP tools that act as judges.request_params: forwarded to both optimizer and evaluator LLMs (temperature, max tokens, strict schema enforcement).llm_factory: automatically injected based on theprovideryou specify; override if you need custom model selection or instrumentation.evaluator_optimizer.refinement_history: list of dicts containingresponseandevaluation_resultper attempt—useful for UI timelines or telemetry.
Pairing with other patterns
- Router + evaluator: Route to a specialised agent, then run the evaluator loop before returning to the user.
- Parallel + evaluator: Run multiple evaluators in parallel (e.g. clarity, policy, bias). Feed the aggregated verdict back into the optimizer.
- Deep research failsafe: Wrap sections of a deep orchestrator plan with an evaluator-optimizer step to enforce domain-specific QA.
Operational tips
- Evaluator instructions should reference the previous feedback: the default prompt asks the optimizer to address each focus area. Ensure your instruction echoes that requirement.
- Call
await evaluator_optimizer.get_token_node()to see how many tokens each iteration consumed (optimiser vs evaluator). - Log or persist
refinement_historywhen you need postmortem evidence of what the evaluator flagged and how the optimizer reacted. - Combine with OpenTelemetry (
otel.enabled: true) to capture spans for each iteration, including evaluation scores and decision rationale.
Example projects
- workflow_evaluator_optimizer – job application cover letter refinement with evaluator feedback surfaced via MCP tools.
- Temporal evaluator optimizer – durable loop running under Temporal with pause/resume.