When to use it
- You need several specialists to analyse the same request from different angles (e.g. proofread, fact-check, style review).
- You want deterministic aggregation of multiple perspectives into a single response.
- You have functions or agents that can run concurrently and do not depend on each other’s intermediate state.
- You want a cheap way to blend deterministic helpers (regex, heuristics) with heavyweight LLM agents.
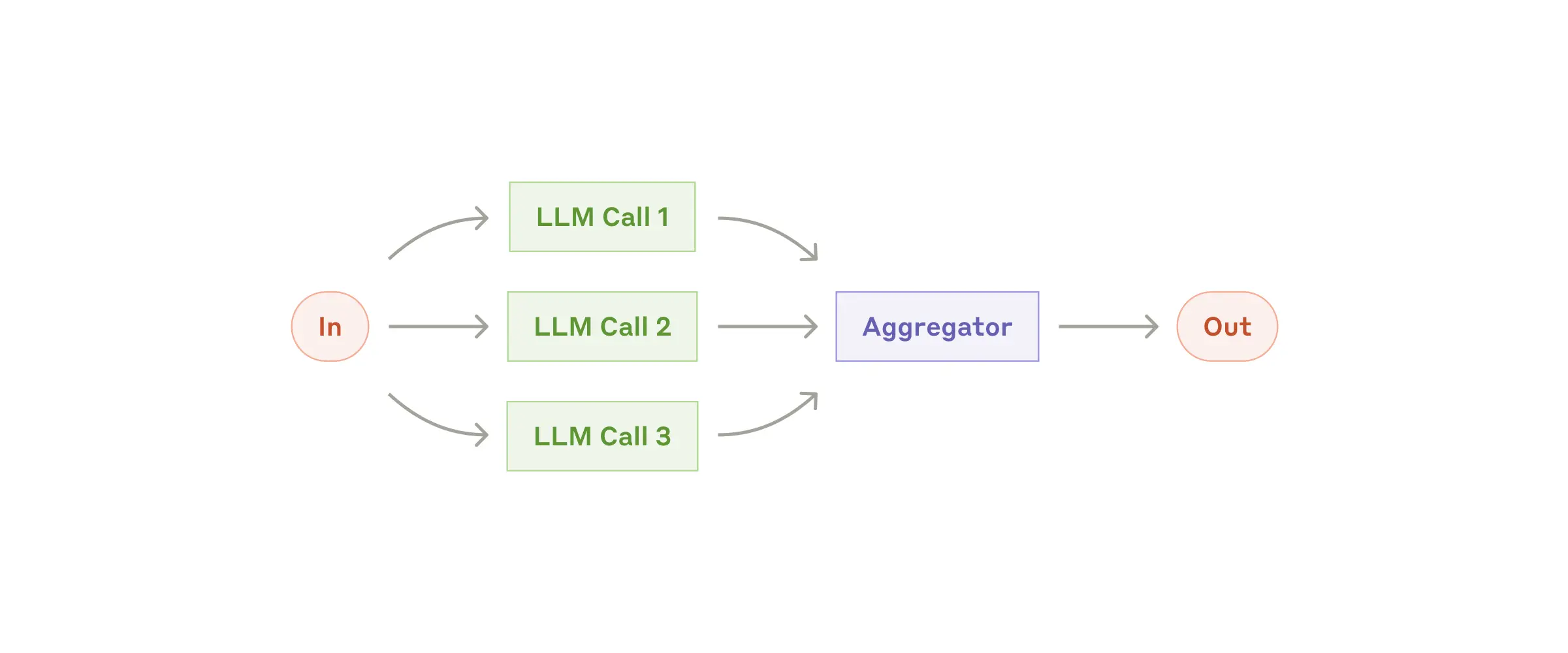
How it works
create_parallel_llm(...) returns a ParallelLLM composed of two primitives:
- FanOut (
fan_out.py) launches every worker concurrently. Workers can beAgentSpec, pre-builtAgent/AugmentedLLM, or plain callables viafan_out_functions. - FanIn (
fan_in.py) collects the responses and hands aFanInInputstructure to your aggregator. The aggregator can also be anAgentSpec, anAugmentedLLM, or a deterministic function.
Quick start
create_parallel_llm accepts AgentSpec, already-instantiated Agent/AugmentedLLM, or plain Python callables. Every worker receives the same prompt; the aggregator receives a structured summary of all responses and returns either a list of CreateMessageResult objects or a single string, depending on whether you call generate or generate_str.
Working with the aggregator input
FanIn accepts several shapes (dicts or lists). For example, you can use a deterministic aggregator:Operational tips
- Throttle concurrency by setting
executor.max_concurrent_activitiesinmcp_agent.config.yaml. The parallel workflow uses the shared executor, so the limit applies across your entire app. - Mix deterministic helpers via
fan_out_functionsfor cheap signals (regex extractors, heuristics) alongside heavyweight LLM calls. - Inspect token/latency costs with
await parallel.get_token_node()—each fan-out worker appears as a child node, making it easy to spot the expensive branch. - Handle stragglers by adjusting
RequestParams.timeoutSecondsor adding retry logic inside the worker agents. - Reuse workers by instantiating AugmentedLLMs once and passing them directly into
fan_outto avoid repeated attachment overhead.
Example projects
- workflow_parallel – proofreader/fact-checker/style-enforcer with graded aggregation.
- Temporal parallel workflow – demonstrates durable fan-out execution using Temporal as the engine.